요약
- 가상 스레드는 CPU성능을 높이는 기술이 아닌, 대기 중인 스레드의 점유 비용을 낮추는 동시성 모델이다.
- 스파이크 트래픽 환경에서 I/O-bound 작업은 가상 스레드로 인해 큐 대기와 p95 지연이 크게 줄어들었다.
- CPU-bound 작업에서는 스레드 모델 변경만으로 유의미한 성능 차이가 나타나지 않았다.
- 가상 스레드는 병목을 제거하기보다, 병목의 위치를 스레드에서 다른 계층(DB, 외부 API 등)으로 이동시킨다.
- 따라서 가상 스레드 도입은 성능 최적화 문제가 아니라, 백프레셔/타임아웃/제한 등의 설계를 포함한 시스템 설계 문제로 여겨야한다.
문제
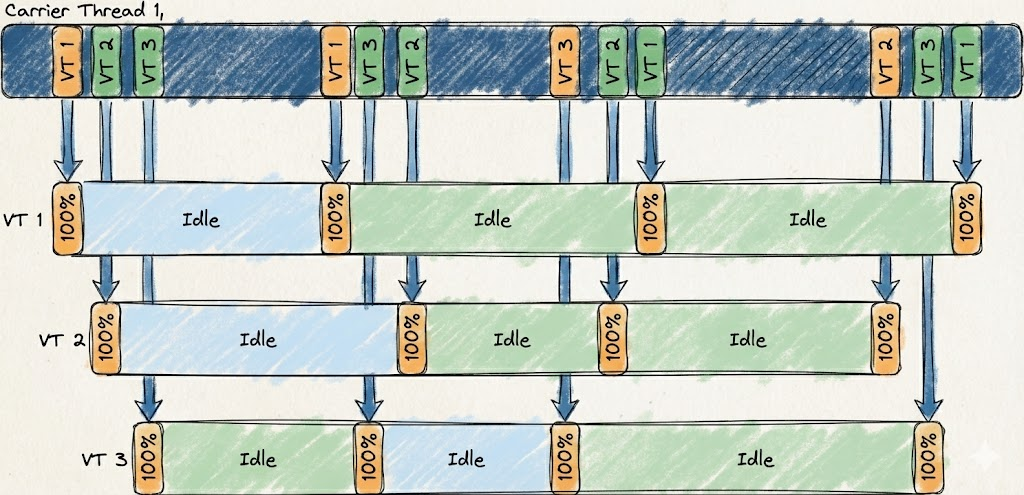
Java 21에서 가상스레드가 도입되었다. 개인적으로 가상 스레드는 넷플릭스 테크 블로그 아티클 "Java 21 Virtual Threads - Dude, Where's My Lock?"을 읽으면서 처음 접하게 되었다. 해당 아티클은 가상 스레드가 Synchrnonized 블록을 만나면서 pinned 되는 현상을 발견하는 과정에 대해 서술하며 가상 스레드의 내부 동작과 한계를 흥미롭게 다루고 있다.
자연스럽게 여러 질문들을 가질 수 밖에 없다. 가상 스레드는 과연 어떤 조건에서 실제로 의미 있는 성능 개선을 제공하는가? 모든 서버 애플리케이션에서 기본 선택지가 될 수 있는가? 아니면 특정 워크로드에서만 효과적인 기술인가?
이 글은 가상 스레드의 내부 구현이 아니라, 스레드 모델 차이가 실제 성능 특성에 어떤 영향을 미치는지를 확인하기 위해 간단한 벤치마킹을 통해 I/O-bound와 CPU-bound 시나리오를 비교한다.
테스트 방법
환경과 설정
스레드 모델 차이에 따른 성능 특성을 관찰하는 것이 목적이므로, 환경 복잡도를 최소화한 로컬 환경에서 수행했다.
- CPU: Apple M3 Pro
- Memory: 36GB
- OS: macOS
- JDK: Java 21
- Framework: Spring Boot
- Load Tool: k6
네트워크 지연, 컨테이너 스케줄링 등 스레드 모델과 직접 관련없는 변수를 배제하기 위해 컨테이너(Docker)나 분산 환경은 사용하지 않았다.
서버 설정
Spring Boot의 내장 톰캣을 사용했으며, 스레드 모델 비교를 위해 다음 설정을 적용했다.
spring.application.name=e-hr-lab
server.port=9090
# Server Configuration
spring.threads.virtual.enabled=true
server.tomcat.threads.max=200- spring.threads.virtual.enabled 옵션을 통해 가상 스레드 기반 요청 처리를 활성화 했다.
- server.tomcat.threads.max 값은 플랫폼 스레드 환경에서의 동시 처리 한계를 명확히 드러내기 위해 비교 기준으로 고정했다.
시나리오
출근 처리와 같이 짧은 시간에 동시 요청이 몰리는 스파이크 트래픽 상황을 가정했다. 요청은 일정하게 증가하는 정상 로드(steady load)가 아닌, 다수의 요청이 동시에 유입되는 상황에서 처리된다. 시나리오는 다음 두 가지로 구성했다:
- I/O-bound (Blocking)
- 요청 마다 300ms 대기를 넣어 대기 중에도 스레드를 점유하는 상황을 만들었다.
- 이 경우 플랫폼 스레드는 동시성이 커질수록 요청이 큐에 대기하며 추가 지연(Queueing Delay)이 생길 것으로 예상했다.
- 반면 가상 스레드는 대기 비용을 낮추므로 p95가 베이스 레이턴시인 약 300ms에 가까워지는 패턴을 기대했다.
- CPU-bound (Computation)
- 반복 연산(for-loop)으로 CPU를 점유하게 하여 스레드가 아닌 CPU가 병목인 상황을 만들었다.
- 이 경우 스레드 모델 변경만으로 유의미한 개선이 발생하기 어렵고, 처리량/지연이 CPU 포화 수준에 의해 결정될것으로 예상했다.
두 시나리오는 DB 네트워크를 배제하고 컨트롤러에서 직접 수행하여, 병목 요인을 최소화한 상태에서 스레드 모델 차이만 관찰하는 목적으로 한다. DB 커넥션 풀, 락 경쟁이 포함된 시나리오는 다음 실험으로 다룰 예정이다.
ThreadTestController
@RestController
@RequestMapping("/thread")
public class ThreadTestController {
@GetMapping("/io")
public String ioBound() throws InterruptedException {
// Simulate IO-bound operation
Thread.sleep(300);
return "IO Done";
}
@GetMapping("/cpu")
public String cpuBound() {
long result = 0;
// Simulate CPU-bound operation
for (long i = 0; i < 2_000_000_000L; i++) {
result += i;
}
return "CPU Done: " + result;
}
}
k6 스크립트
import http from 'k6/http';
import { check } from 'k6';
export const options = {
vus: 500, // 동시 접속자 500명 (CPU 테스트 시 컴퓨터 보호를 위해 조금 줄임)
duration: '15s', // 15초 테스트
};
export default function () {
const res = http.get('http://localhost:9090/thread/cpu');
// const res = http.get('http://localhost:9090/thread/io');
check(res, { 'status is 200': (r) => r.status === 200 });
}
테스트 결과
처리량 비교 (Throughput)
I/O-bound 시나리오에서는 가상 스레드 환경에서 처리량이 약 2.5배 높게 측정되었다. 플랫폼 스레드 환경에서는 동시 요청이 증가할수록 스레드가 대기 상태에 있음에도 OS스레드가 점유하면서 요청이 큐잉되는 상황임을 확인할 수 있었다.
반면 가상 스레드는 대기 중인 요청이 OS 스레드를 점유하지 않기 때문에 동일한 시간 동안 더 많은 요청을 처리할 수 있었다. 이로 인해 스파이크 상황에서도 플랫폼 스레드 대비 큐 대기로 인한 처리량 저하가 덜 관찰되었다.
CPU-bound 시나리오에서는 두 스레드 모델 간 처리량 차이가 어의 없었으며, 가상 스레드 환경에서는 오히려 소폭 낮은 처리량이 관측되었다. 이는 CPU 연산량에 크게 의존하고 있음을 나타낸다.

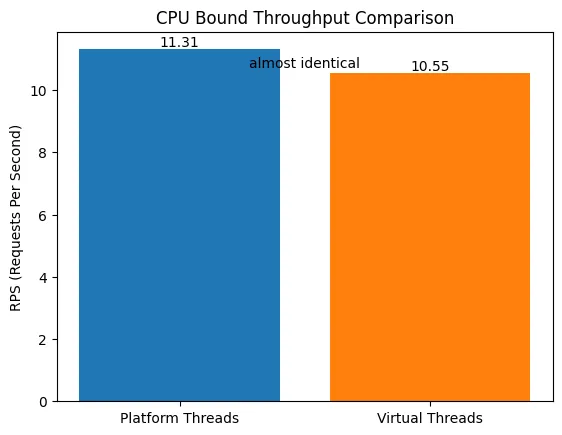
Table 1. I/O vs. CPU Bound 처리량
| 시나리오 (Scenario) | Platform Threads (RPS) | Virtual Threads (RPS) | 증감률 (Change) |
| I/O Bound (Blocking) | 651.68 | 1,625.67 | +149.4% (2.5배) |
| CPU Bound (Computation) | 11.31 | 10.55 | -6.7% (성능 저하) |
지연 시간 비교 (Latency)
레이턴시는 사용자가 직접체감하는 성능 지표이며, 스파이크 트래픽 상황에서는 평균값보다 p95가 더 중요한 의미를 갖는다.
I/O-bound 시나리오에서 가상 스레드의 p95 지연 시간은 약 315ms로 측정되었다. 이는 베이스 레이턴시인 300ms와 거의 유사한 값으로, 동시 요청이 급증하더라도 요청이 큐에서 대기하지 않고 즉시 실행 상태로 진입했음을 의미한다. 반면 플랫폼 스레드 환경에서는 평균 지연이 약 747ms, p95는 900ms 이상으로 관측되었다. 베이스 레이턴시 대비 약 400ms 이상의 추가 지연이 발생했으며, 이는 스레드 풀 한계로 인해 요청이 큐 대기한 시간으로 해석할 수 있다.
CPU-bound시나리오 에서는 두 스레드 모델 모두 높은 지연 시간을 보였으며, p95 기준에서도 유의미한 차이는 나타나지 않았다. 이 역시 해당 시나리오에서의 병목이 스레드 모델이 아닌 CPU 포화 상태에 있음을 뒷받침한다.

Table 2. I/O Bound (Latency)
| 지표 (Metric) | Platform Threads (ms) | Virtual Threads (ms) | 차이 (Difference) |
| 평균 응답 속도 (Avg) | 747.40 ms | 306.64 ms | 2.4배 빠름 |
| 하위 95% 속도 (p95) | 908.46 ms | 315.55 ms | 2.8배 빠름 |
Table 3. CPU Bound (Latency)
| 지표 (Metric) | Platform Threads (sec) | Virtual Threads (sec) | 차이 (Difference) |
| 평균 응답 속도 (Avg) | 29.98 s | 22.64 s | 데이터 편차 있음 |
| 하위 95% 속도 (P95) | 44.03 s | 42.63 s | 비슷함 |
실무관점에서 결론
가상 스레드를 검토해볼 만한 조건
실험 결과를 통해 가상 스레드는 CPU를 더 빠르게 만드는 기술이 아니라, CPU를 사용하지 않는 대기 시간 동안 스레드 점유 비용을 낮추는 기술이다. 따라서 I/O-bound와 같이 스레드가 대기 상태에 머무는 시간이 긴 경우에만 의미 있는 성능 개선이 나타난다.
아래 예시들은 서버의 CPU를 거의 사용하지 않지만 스레드를 오래 붙잡는 상황들이다:
- DB I/O 대기 (가장 전형적인 상황)
- 요청 흐름: (1)HTTP 요청 수신, (2)DB 쿼리 실행, (3) DB 응답 대기 (수십~수백 ms)
- 외부 API 호출 (HTTP Client)
- 예) 결제 승인, 인증 서버 호출, 외부 SaaS 연동
- 스토리지, 파일 I/O
- 예) 로그 파일 읽기, 대용량 파일 업로드/다운로드, 객체 스토리지(S3 등) 접근
- 동기식 레거시 연동 (sychronized + blocking I/O)
반대로 효과 없는 경우는 CPU-bound 작업이다. 스레드는 계속 RUNNABLE 상태이며 CPU가 병목으로 존재한다. 가상 스레드는 이러한 상황에서 '유의미한' 이점을 제공하기 어렵다.
성능 실험 결과를 그대로 적용하면 안되는 이유
가상 스레드는 결국 '기다림'을 저렴하게 만드는 기술이다. 가상 스레드는 내 쪽의 기다림을 싸게 만들지만, 상대방(다운스트림)의 기다림과 부하를 고려해야한다. 병목이 전이되는 상황은 실제 서비스 환경에서도 관찰된다. 카카오페이 테크 블로그에서 RDB와 Key-value 스토어로 구성된 멀티 티어 환경 이를 검증하기 위한 테스트를 소개하고 있다.
예를 들어, 상대방은 DB인 경우 커넥션 수, 락, 디스크 I/O가 병목이 된다. 외부 API는 QPS 제한과 Rate Limit이 걸릴 수 있다. 이러한 상황에서 가상 스레드가 도입되면 타임아웃으로 오류가 발생하거나 재시도가 폭증할 수 있다. 내 서버는 문제가 없지만 전체 시스템은 불안정해지는 결과를 낳는다.
따라서, 명시적인 백프레셔를 두어 무제한으로 요청을 내보내서는 안된다. 동시 처리 제한이나 큐잉 혹은 429 상태코드에 대한 폴백이 필요하다. 상대방의 시스템이 무너졌을때를 고려해서 적절한 타임아웃이나 제한적인 재시도 전략도 고려해본다. 실패를 빠르게 파악하고 서킷 브레이커를 오픈할 수 있다. 결국 가상 스레드 도입은 처리량을 늘리는 문제가 아니라, 시스템 간 책임과 경계를 어디에 둘 것인가에 대한 설계 문제이다.
참고 자료
- Java 21 Virtual Threads - Dude, Where's My Lock? | Vadim Filanovsky et al. (2024, Netflix Technology Blog)
- [Project Loom] Virtual Thread에 봄(Spring)은 왔는가 | Ro (2024, Kakao Pay Tech)
- Java의 미래, Virtual Thread | 김태헌 (2023, 우아한 형제들 기술블로그)
- Virtual Threads in Java - Deep Dive with Examples | Sven Woltmann (2025)



